Developer Documentation
LLM app evaluation at your fingertips
Evaluate with confidence
Orchestrator Agnostic Evaluation: Break Free from Rigid Frameworks
With our evaluations, you can focus on building and refining your application without worrying about prompting or model lock-in, embracing true flexibility and freedom from rigid frameworks.
Comprehensive Metrics, Unshackled: Gain Insights Without Constraints
Our evaluation approach offers the flexibility to leverage familiar model-based metrics like faithfulness and context relevance, as well as statistical metrics like MRR and MAP, empowering you to gain comprehensive insights tailored to your application's needs.
Read the Docs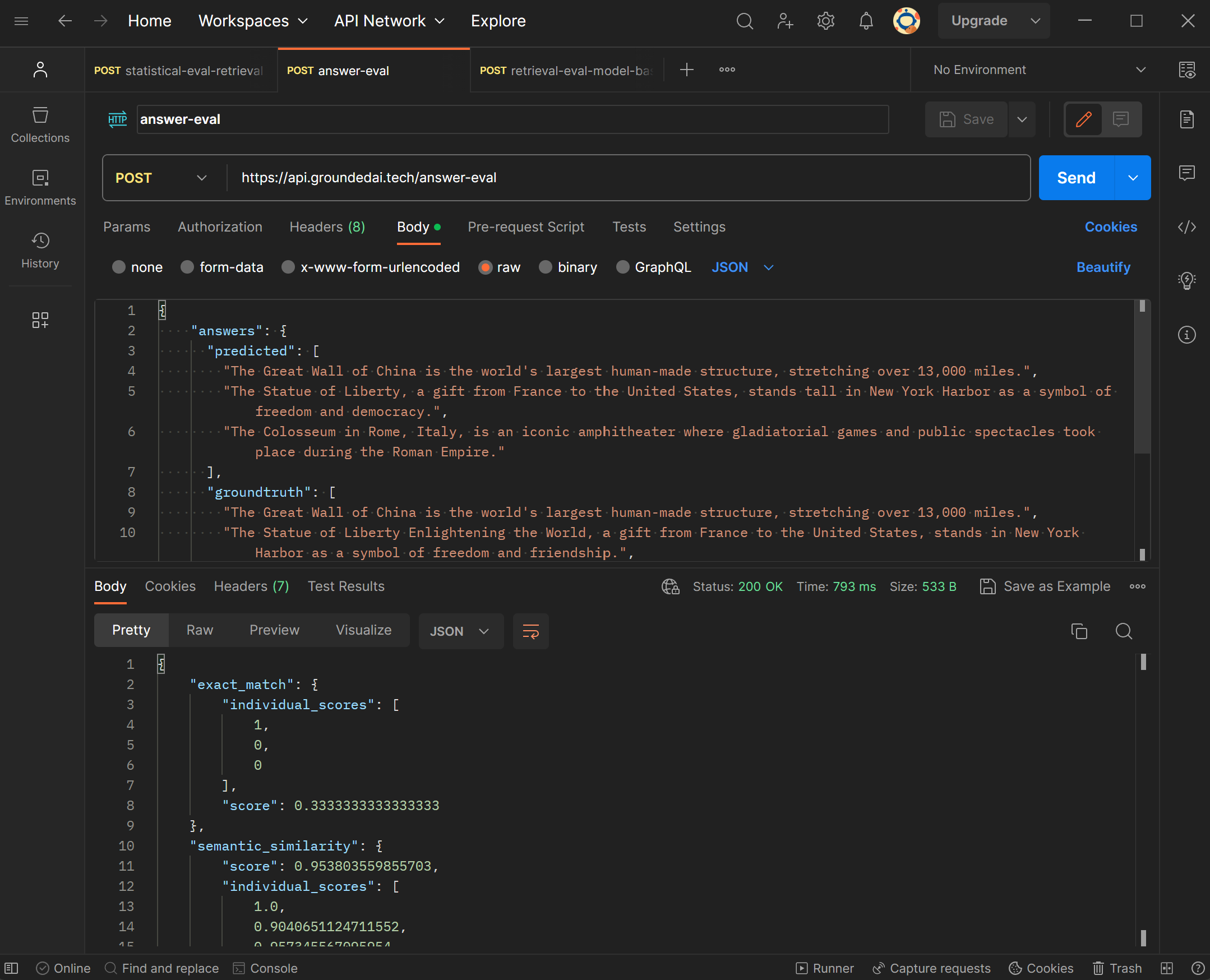
GroundedAI Evaluation Library
The grounded_ai package is a powerful tool developed by GroundedAI to evaluate the performance of large language models (LLMs) and their applications. It leverages small language models and adapters to compute various metrics, providing insights into the quality and reliability of LLM outputs.
Installation
You can install the grounded_ai package using pip:
!pip install grounded-ai==0.0.9-alpha
Evaluators
The grounded_ai package provides several evaluators to assess different aspects of LLM performance. Here's an overview of the available evaluators and their usage:
-
Toxicity Evaluator
The ToxicityEvaluator class is used to evaluate the toxicity of a given text.
from grounded_ai.evaluators.toxicity_evaluator import ToxicityEvaluator toxicity_evaluator = ToxicityEvaluator() toxicity_evaluator.warmup() data = [ "That guy is so stupid and ugly", "Bunnies are so fluffy and cute" ] response = toxicity_evaluator.evaluate(data) print(response) # Output: {'toxic': 1, 'non-toxic': 1, 'percentage_toxic': 50.0, 'reasons': []} -
Hallucination Evaluator
The HallucinationEvaluator class is used to evaluate whether a given response to a query is hallucinated or truthful based on the provided context or reference.
from grounded_ai.evaluators.hallucination_evaluator import HallucinationEvaluator hallucination_evaluator = HallucinationEvaluator(quantization=True) hallucination_evaluator.warmup() references = [ "The chicken crossed the road to get to the other side", "The apple mac has the best hardware", "The cat is hungry" ] queries = [ "Why did the chicken cross the road?", "What computer has the best software?", "What pet does the context reference?" ] responses = [ "To get to the other side", # Grounded answer "Apple mac", # Deviated from the question (hardware vs software) "Cat" # Grounded answer ] data = list(zip(queries, responses, references)) response = hallucination_evaluator.evaluate(data) response # Output # {'hallucinated': 1, 'truthful': 2, 'percentage_hallucinated': 33.33333333333333} -
RAG Relevance Evaluator
The RagRelevanceEvaluator class is used to evaluate the relevance of a given text with respect to a query.
from grounded_ai.evaluators.rag_relevance_evaluator import RagRelevanceEvaluator rag_relevance_evaluator = RagRelevanceEvaluator() rag_relevance_evaluator.warmup() data = [ ["What is the capital of France?", "Paris is the capital of France."], #relevant ["What is the largest planet in our solar system?", "Jupiter is the largest planet in our solar system."], #relevant ["What is the best laptop?", "Intel makes the best processors"] #unrelated ] response = rag_relevance_evaluator.evaluate(data) response # Output # {'relevant': 2, 'unrelated': 1, 'percentage_relevant': 66.66666666666666}
Usage
Install the grounded_ai package using pip.
Import the desired evaluator class from the grounded_ai.evaluators module.
Create an instance of the evaluator class and call the warmup method to load the base model and merge the adapter.
Prepare the input data in the required format (e.g., a list of texts for the ToxicityEvaluator, or a list of tuples containing queries, responses, and references for the HallucinationEvaluator).
Call the evaluate method of the evaluator instance with the input data.
The evaluate method returns a dictionary containing the evaluation results, such as the counts of toxic/non-toxic texts, hallucinated/truthful responses, or relevant/unrelated texts, along with the corresponding percentages.
For more detailed information on each evaluator, including the input data format and the structure of the output dictionary, refer to the docstrings and comments within the source code. Example usage is shown at Examples
Try GroundedAI today
Grounding AI in Truth: Pioneering Evaluation for Language Model Application Anchored in Reality.
Start Evaluating